


- Accueil
- Volume 15 (2011)
- numéro 3
- Principaux modèles utilisés en régression logistique


Visualisation(s): 23155 (172 ULiège)
Téléchargement(s): 1365 (17 ULiège)

Principaux modèles utilisés en régression logistique

Notes de la rédaction
Reçu le 18 janvier 2010, accepté le 16 novembre 2010
Résumé
La régression est une technique très couramment utilisée pour décrire la relation existant entre une variable à expliquer et une ou plusieurs variables explicatives. Lorsque la variable à expliquer est une variable qualitative, la régression linéaire classique au sens des moindres carrés doit être abandonnée au profit de la régression logistique. Si la variable à expliquer ne présente que deux modalités, on utilise la régression logistique binaire. Si elle présente plus de deux modalités et si celles-ci ne sont pas ordonnées, on doit employer la régression logistique polychotomique nominale. Enfin, si la variable à expliquer présente plus de deux modalités et que celles-ci sont ordonnées, la méthode à exploiter est la régression polychotomique ordinale. Cette note décrit ces trois méthodes de régression logistique et, pour la régression ordinale, elle présente les trois modèles les plus souvent utilisés. Ces modèles sont illustrés par un exemple relatif au dépérissement du chêne en Région wallonne (Belgique).
Abstract
Main models used in logistic regression. Regression is a commonly used technique for decribing the relationship between a response variable and one or more explanatory variables. When the response variable is a categorical variable, usual regression based on ordinary least squares should be replaced by logistic regression. Binary logistic regression should be used to perform a regression on a dichotomous response. Nominal polytomous logistic regression applies to a categorical response variable that has more than two levels with no natural ordering. And ordinal polytomous logistic regression is used when the response is a categorical variable that has more than two levels with a natural ordering. This note gives an overview of these logistic regression methods and describes three models commonly used when performing ordinal logistic regression. These models are illustrated by an example related to oak decline in the Walloon Region (Belgium).
Table des matières
1. Introduction
1La régression linéaire, simple ou multiple, est une méthode statistique très couramment utilisée dans le traitement des données, en particulier dans une démarche de modélisation.
2Elle consiste à mettre en relation une variable à expliquer y avec une ou plusieurs variables explicatives x1, x2, ..., xp, appelées prédicteurs. La méthode est cependant limitée aux situations où la variable à expliquer est une variable quantitative dont la distribution, pour une valeur fixée des prédicteurs, est normale. Elle ne devrait notamment pas être utilisée lorsque la variable y est une variable qualitative. Pour de telles situations, la méthode indiquée est la régression logistique qui offre plusieurs variantes en fonction du nombre et de la nature des classes de la variable à expliquer.
3La première méthode, appelée régression logistique binaire (binary logistic regression), correspond au cas où la variable y comporte uniquement deux classes, les individus étant décrits par la présence ou l'absence d'un caractère donné. Par exemple, des individus (parcelles, plantes, animaux, etc.) peuvent être attaqués ou non par un parasite, être fertiles ou non, être porteurs ou non d'une tare, etc.
4La deuxième méthode, appelée régression logistique polychotomique nominale (polytomous nominal logistic regression), permet de traiter les cas où la variable à expliquer possède plus de deux classes si celles-ci ne peuvent pas être ordonnées ou si on ne souhaite pas tenir compte de l'ordre dans le cas où elles seraient ordonnées. Une telle situation se présente par exemple si des individus sont caractérisés par l'appartenance à une espèce donnée, par une couleur ou par le choix d'une réponse à une question posée parmi trois propositions telles que « oui », « non », « ne sait pas ».
5Enfin, la troisième méthode, appelée régression polychotomique ordinale (polytomous ordinal regression), concerne les situations où la variable y présente plus de deux modalités qui peuvent être ordonnées et dont on souhaite tenir compte de l'ordre. Un exemple typique est la description de l'intensité de l'attaque d'individus par un parasite, cette description étant réalisée par exemple sur la base d'une échelle à quatre niveaux notés A, B, C et D, le niveau A représentant l'absence d'attaque, le niveau B une attaque faible, le niveau C une attaque modérée et le niveau D une attaque forte.
6Dans la pratique, il arrive fréquemment que l'appartenance aux classes soit décrite par des codes numériques. Ainsi, au lieu de noter les degrés d'attaque par A, B, C ou D, on peut les identifier par les codes 0, 1, 2 ou 3. Ce codage est purement arbitraire et les méthodes logistiques ne considèrent jamais les valeurs numériques en tant que telles, mais simplement comme des noms de modalités. Dans le cas d'une variable ordinale codée, il est d'ailleurs possible que l'ordre logique des classes ne corresponde pas à l'ordre donné par les nombres utilisés comme codes. Une telle situation est cependant à déconseiller car elle est de nature à perturber inutilement l'interprétation des résultats.
7Pour les trois méthodes citées ci-dessus, le but est de modéliser une ou plusieurs probabilités liées à l'appartenance aux classes, en fonction d'un ou de plusieurs prédicteurs, qui peuvent eux-mêmes être des variables quantitatives ou des variables qualitatives, supposées parfaitement connues.
8L'objectif de cette publication est de présenter ces méthodes, de manière succincte, en insistant sur l'interprétation des modèles.
9Après cette introduction, nous examinons d'abord le modèle de régression binaire, puis le modèle polychotomique nominal. Nous passons ensuite en revue trois modèles pour la régression polychotomique ordinale. Nous clôturons par une discussion relative aux modèles polychotomiques.
10Dans un but de simplification, les différents modèles sont présentés dans le cas de la régression sur un seul prédicteur, noté x. La généralisation au cas de plusieurs prédicteurs est immédiate : il suffit, dans les notations des modèles, de remplacer le coefficient de régression et la variable explicative par des vecteurs de coefficients et de variables.
11Nous illustrons les différents modèles par un exemple traité antérieurement par Gillet (2005 ; 2007) et relatif au dépérissement de chênes dans le Condroz et l'Ardenne belge. Les données utilisées concernent le niveau de dépérissement de 230 chênes et l'altitude des stations dans lesquelles ces chênes ont été observés. Le dépérissement a été évalué par l'aspect du houppier sur une échelle à quatre niveaux. Le niveau 1 correspond à un dépérissement très faible, le niveau 2 à un dépérissement faible, le niveau 3 à un dépérissement fort et le niveau 4 à un dépérissement très fort. La variable à expliquer y est donc une variable qualitative ordinale à quatre classes et la variable explicative x est l'altitude. Des modifications dans ces variables sont cependant apportées afin de permettre l'illustration des différentes situations. Les modèles qui sont ajustés aux données servent uniquement d'exemples et ne représentent pas nécessairement des modèles adéquats pour la modélisation du dépérissement, celui-ci étant lié à d'autres facteurs que la seule altitude.
12On notera que la régression logistique soulève bien d'autres problèmes que la définition du modèle : problèmes d'inférence statistique, de critères de qualité de l'ajustement et de choix de variables explicatives, notamment. Ces aspects ne sont pas abordés dans cette note. Des informations complémentaires à ce sujet sont données dans les ouvrages consacrés, totalement ou partiellement, à la régression logistique. Parmi ceux-ci, nous citerons les livres d'Agresti (2002) et Hosmer et al. (2000). Pour la régression binaire, des informations sont également données dans le document de Duyme et al. (2006).
2. Modèle logit pour données binaires
13Lorsque la variable à expliquer possède deux modalités codées par exemple y = 1 et y = 2, l'objectif est de modéliser, en fonction de x, la probabilité d'appartenance à une des deux catégories, appelée succès ou évènement (success ou event). Nous notons cette probabilité π (xi), ou plus simplement π.
14Les probabilités π(xi) évoluent cependant de manière non linéaire en fonction de xi. De plus, la variance de ces probabilités varie avec xi. Il en résulte que l'utilisation d'un modèle linéaire exprimant π en fonction de x et ajusté par les moindres carrés classiques n'est pas une solution adéquate, les conditions d'application de la régression – linéarité et constance de la variance conditionnelle – n'étant pas remplies. Pour cette raison, on effectue une transformation de la probabilité de succès g(π (xi)). Cette transformation s'appelle fonction de lien (link function), et par la suite sera notée simplement g.
15Plusieurs fonctions de lien existent mais la plus couramment utilisée est la fonction logit :
16g = logit(π) = loge [π / (1 - π)],
17parce qu'elle conduit à une interprétation simple des résultats, mais aussi pour des raisons théoriques (Collett, 1999).
18Le modèle de régression s'écrit alors :
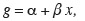
19où α et β sont des paramètres à estimer, le plus souvent par la méthode du maximum de vraisemblance. La transformation inverse permet alors de retrouver les probabilités estimées en fonction de x :
20π = exp(g) / [1 + exp(g)],
21qui sont toujours comprises entre 0 et 1.
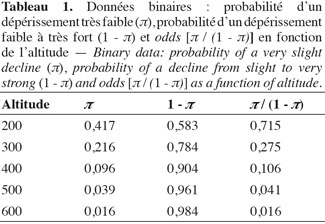
22Pour une valeur xi donnée, le rapport entre la probabilité de succès π et la probabilité d'échec 1 - π est appelé chance ou cote, mais est le plus souvent désigné par le terme anglais odds. Il est égal à :
23π / (1 - π) = exp(g).
24Lorsque la probabilité de succès est plus grande que la probabilité d'échec, l'odds est supérieur à l'unité. Si les deux probabilités sont égales, l'odds est égal à 1. Enfin, si la probabilité de succès est plus petite que la probabilité d'échec, l'odds est inférieur à l'unité.
25Si on considère maintenant le rapport entre les odds relatifs à xi + 1 et à xi, on définit le rapport de chances ou le rapport des cotes, plus souvent désigné par le terme anglais odds ratio, qui est directement lié au coefficient de régression β :
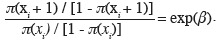
26L'odds ratio n'est jamais négatif, mais n'a pas de borne supérieure. Une valeur égale à l'unité signifie que la cote pour xi est égale à la cote pour xi + 1. Dans cette situation, la variable explicative n'a donc pas d'effet sur la cote et le coefficient de régression est nul. Un odds ratio inférieur à l'unité correspond à un coefficient de régression négatif et signifie que la probabilité de succès diminue lorsque x augmente. Un odds ratio supérieur à l'unité correspond à un coefficient de régression positif et signifie que la probabilité de succès augmente lorsque x augmente.
27Lorsque la variable explicative est continue, l'odds ratio est parfois très proche de 1, une différence d'une unité de x étant insuffisante pour modifier de manière sensible les rapports des cotes. Dans ce cas, il peut être préférable de calculer l'odds ratio pour une modification δ de la variable explicative. On a alors :
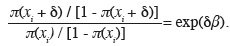
28Pour illustrer la régression logistique binaire à partir des données relatives au dépérissement du chêne, nous regroupons les classes pour lesquelles le code est supérieur à 1. Après ce regroupement, la première classe correspond au dépérissement très faible et la deuxième correspond au dépérissement faible à très fort. L'appartenance à la première classe est choisie comme l'évènement. Le modèle ajusté est le suivant :
29g = 1,5714-0,009533 x.
30La valeur négative du coefficient de régression indique que la probabilité d'être dans la classe « dépérissement très faible » diminue avec l'altitude. Si on détermine, à titre d'exemple, cette probabilité pour une altitude de 200 m et pour une altitude de 300 m, en utilisant la relation donnée ci-dessus, on trouve :
31π (200) = 0,417 et π (300) = 0,216.
32Ces valeurs correspondent à des probabilités estimées par le modèle de régression. Elles devraient donc être notées :
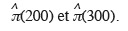
33Toutefois, pour alléger les notations, nous choisissons de représenter systématiquement les valeurs théoriques et les valeurs estimées par le même symbole, le contexte permettant de lever toute ambigüité. À partir de ces probabilités, on vérifie bien que, pour δ = 100, l'odds ratio est égal à :
34π(300) / [1 - π(300)] = exp[(100)(-0,009533)] = 0,385.
35π(200) / [1 - π(200)]
36Lorsque l'altitude augmente de 100 m, le rapport entre la probabilité d'un dépérissement très faible et un dépérissement faible à très fort est donc multiplié par 0,39 ou encore divisé par 2,6 environ.
37Le tableau 1 donne, en fonction de l'altitude, les probabilités π d'être dans la classe de dépérissement très faible, les probabilités 1 - π d'être dans la classe faible à très fort, ainsi que les rapports de ces deux probabilités qui sont les odds. On vérifie bien ainsi que le rapport entre un odds et l'odds précédent est constant et égal, aux erreurs d'arrondis près, à 0,385.
3. Modèle logit pour données nominales
38La régression logistique polychotomique nominale est une extension naturelle de la régression binaire qui permet de prendre en compte un nombre de catégories supérieur à deux. Soit y = j, l'indication de l'appartenance d'un individu à la catégorie j. Une catégorie est choisie comme référence et l'appartenance à cette catégorie est considérée comme l'évènement de référence (reference event). Pour une variable à expliquer à k modalités et en prenant arbitrairement la ke modalité comme référence, on modélise l'évolution, en fonction de x, de k - 1 probabilités conditionnelles :
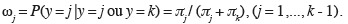
39Les logits correspondant à ces probabilités sont appelés logits pour une catégorie de référence (baseline-category logits) :
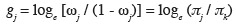
40et sont modélisés en fonction de x par les relations suivantes :
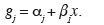
41Un résultat similaire pourrait être obtenu en ajustant indépendamment k - 1 régressions binaires, chacune de ces régressions étant ajustée au sous-ensemble d'individus appartenant à la catégorie j et à la catégorie k. Les ajustements séparés donneraient cependant des paramètres estimés légèrement différents et moins efficaces que l'ajustement simultané des k - 1 équations.
42Disposant des k - 1 équations, on peut déterminer les odds :
43πj / πk = exp(gj)
44et retrouver les probabilités d'appartenance à chacune des classes par les relations suivantes :
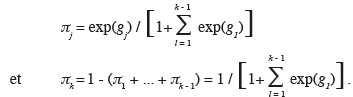
45Les coefficients de régression βj sont liés aux odds ratios :
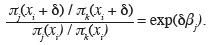
46Il en résulte qu'un coefficient de régression positif signifie que l'odds est plus grand en xi + δ qu'en xi ou encore que la probabilité d'appartenance à la catégorie j augmente plus vite ou diminue moins vite quand x augmente que la probabilité d'appartenance à la catégorie de référence. Une valeur positive ne signifie donc pas automatiquement que la probabilité d'appartenance à la catégorie j augmente quand x augmente, comme c'est le cas pour la régression binaire.
47L'interprétation des valeurs numériques obtenues lors de la régression logistique doit bien entendu tenir compte de la catégorie choisie comme référence. Cependant, ce choix n'a pas fondamentalement d'importance, car à partir des résultats obtenus pour une catégorie de référence, on peut très simplement obtenir les résultats pour une autre catégorie de référence, sans refaire une nouvelle maximisation de la fonction de vraisemblance.
48Si on souhaite exprimer les résultats en prenant par exemple comme référence la catégorie 1 alors qu'on dispose des résultats pour la catégorie de référence k, les nouvelles équations, notées g'j s'écriront :
49g'j = gj - g1 et g'k = -g1.
50En effet :
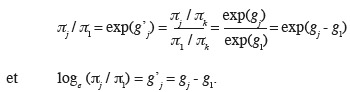
51Pour les données relatives au dépérissement, en prenant la classe 4 comme référence, on obtient les équations suivantes :
52g1 = 6,3514 - 0,016579 x,
53g2 = 4,9582 - 0,008987 x
54et g3 = 2,5449 - 0,004436 x.
55Le tableau 2 donne les probabilités d'appartenance à chacune des catégories en fonction de l'altitude. Il donne également les odds, c'est-à-dire les rapports des probabilités πj / π4. On peut constater que, contrairement à la régression binaire, les probabilités d'appartenance à une classe ne sont plus obligatoirement toujours croissantes ou toujours décroissantes. Ainsi, la probabilité π2 est d'abord croissante et ensuite décroissante. De même, la probabilité π3 décroîtrait à partir d'une certaine altitude, si le domaine de variation de l'altitude était élargi. Par contre, la probabilité π1 est toujours décroissante et la probabilité π4 est toujours croissante avec l'altitude.
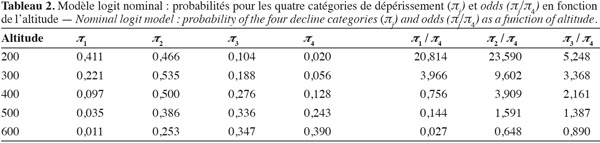
56Les odds ratios, calculés pour une différence d'altitude de 100 m, valent respectivement 0,19, 0,40 et 0,64. Ainsi, quand l'altitude augmente de 100 m, le rapport entre la probabilité d'être dans une classe et la probabilité d'être dans la classe 4 est divisé par 5 pour la classe 1, par 2,5 pour la classe 2 et par 1,6 pour la classe 3. On retrouve également ces valeurs en faisant le rapport de deux valeurs successives dans les trois dernières colonnes du tableau 2.
57On notera que, dans le traitement de cet exemple, on n'a pas pris en compte le caractère ordinal de la variable y : on a considéré quatre classes sans tenir compte du caractère croissant du dépérissement quand on passe du niveau 1 au niveau 4. Les modèles décrits dans les trois paragraphes suivants vont, au contraire, intégrer cette information.
4. Modèle logit basé sur les probabilités cumulées
58Lorsque la variable y traduit l'appartenance à l'une parmi k catégories ordonnées et qu'on souhaite tenir compte de l'ordre de ces catégories, différentes probabilités peuvent être modélisées.
59Une première solution prend en compte les probabilités cumulées :
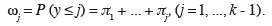
60Les logits s'écrivent :
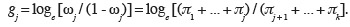
61Ces logits sont appelés logits cumulés (cumulative logits) et, pour une catégorie donnée, ils correspondent aux logits utilisés dans la régression binaire, pour laquelle une catégorie correspondrait aux individus tels que y ≤ j et l'autre catégorie correspondrait aux individus, tels que y > j.
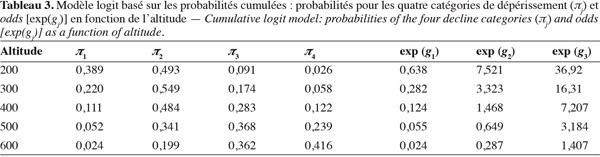
62Les logits sont alors exprimés en fonction de x par les relations :
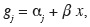
63ajustées par la méthode du maximum de vraisemblance. On remarque que, dans ce modèle, chaque logit cumulé a sa propre ordonnée à l'origine, les
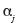
64variant avec j. Par contre, le coefficient de régression β est le même pour toutes les relations. La prise en compte de coefficients de régression constants repose sur une hypothèse de parallélisme qui a l'avantage de conduire à une réduction du nombre de paramètres dans le modèle. La pertinence de cette hypothèse simplificatrice peut éventuellement être testée. Des informations à ce sujet sont données dans la discussion (§ 7).
65Les odds sont égaux à :
66(π1 + ... + πj) / (πj + 1 + ... + πk) = exp (gj)
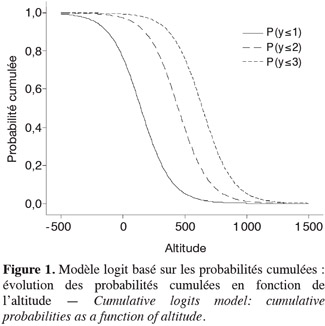
67et les odds ratios relatifs à xi et xi + 1 :
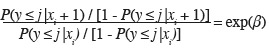
68sont indépendants, non seulement de la valeur de x, mais aussi de la catégorie considérée.
69À partir des logits cumulés, on peut calculer les probabilités cumulées :
70P(y ≤ j) = π1 + ... + πj = exp(gj) / [1 + exp(gj)].
71Disposant des probabilités cumulées, il est évidemment possible d'obtenir, par différence, les probabilités relatives à une classe :
72π1 = P(y ≤ 1)
73πj = P(y ≤ j) - P(y ≤ j - 1) (j = 2, ..., k - 1)
74et πk = 1 - (π1 + ... + πk - 1).
75Pour les données de l'exemple, les équations obtenues sont les suivantes :
76g1 = 1,1837 - 0,008169 x,
77g2 = 3,6514 - 0,008169 x
78et g3 = 5,2426 - 0,008169 x.
79Le tableau 3 donne les probabilités d'appartenance aux catégories et les odds, c'est-à-dire les rapports des probabilités :
80P(y ≤ j) / [1 - P(y ≤ j)], (j = 1, ..., 3).
81L'odds ratio, pour un accroissement de 100 m d'altitude, est égal à :
82exp[(100)(-0,008169)] = 0,442,
83ce qui signifie que, d'une ligne à l'autre du tableau 3, les odds sont divisés par un facteur égal à 2,3 environ.
84La figure 1 donne les probabilités cumulées en fonction de x. Le domaine de variation de x a été volontairement élargi au-delà des valeurs observées afin de mettre en évidence une caractéristique générale des courbes de probabilités cumulées : ces courbes ont la même forme et un déplacement horizontal permettrait de les faire coïncider. Cette situation résulte de l'utilisation dans le modèle d'un coefficient de régression β unique.
5. Modèle logit basé sur les catégories adjacentes supérieures cumulées
85Si l'objectif est de comprendre ce qui distingue les individus qui ont atteint une catégorie donnée mais qui n'atteindront pas les catégories suivantes, on peut s'intéresser aux probabilités suivantes :
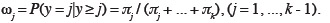
86Les logits (continuation-ratio logits) s'écrivent :
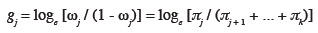
87et correspondent aux logits utilisés dans la régression binaire pour laquelle une catégorie serait formée des individus pour lesquels y = j et l'autre catégorie des individus pour lesquels y > j.
88Ils sont exprimés en fonction de x par les relations :
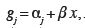
89les coefficients de régression des différents logits étant considérés, par hypothèse, comme identiques.
90Les odds sont donnés par les relations suivantes :
91πj / (πj + 1 + ... + πk) = exp (gj)
92et le rapport entre les odds relatifs à xi et à xi + 1 sont indépendants de x et de la catégorie concernée :
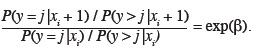
93Les probabilités conditionnelles sont données par :
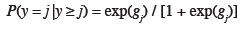
94et les probabilités par catégorie sont obtenues par les relations suivantes :
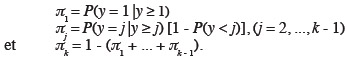
95Dans le cas où on ne souhaiterait pas imposer l'égalité des coefficients de régression des relations donnant les logits, on peut montrer que l'estimation au sens du maximum de vraisemblance de l'ensemble des paramètres est identique à l'estimation qui serait obtenue par la réalisation de k - 1, ajustements indépendants sur les données binaires y = j et y > j, comme expliqué ci-dessus. Cette équivalence est d'ailleurs utilisée en pratique pour l'ajustement du modèle à l'aide des logiciels statistiques, y compris lorsqu'on souhaite un coefficient de régression unique, l'ajustement se faisant alors après un recodage des données.
96Pour l'exemple, on obtient les logits suivants :
97g1 = 0,7595 - 0,006730 x,
98g2 = 2,8542 - 0,006730 x
99et g3 = 3,4897 - 0,006730 x.
100Le tableau 4 donne les probabilités d'appartenance aux différentes catégories ainsi que les odds, en fonction de l'altitude.
101Pour un accroissement de 100 m d'altitude, l'odds ratio vaut :
102exp[(100)(-0,00673)] = 0,510.
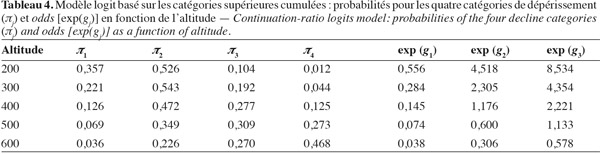
103Le rapport entre la probabilité qu'un chêne soit dans la catégorie j et la probabilité qu'il soit dans une catégorie supérieure à j est divisé par deux quand l'altitude augmente de 100 m, comme le montrent les trois dernières colonnes du tableau 4.
104Si on calculait les probabilités conditionnelles :
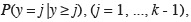
105et qu'on les portait sur un graphique en fonction de x, on obtiendrait trois sigmoïdes décroissantes qui, comme dans le cas de la figure 1, peuvent être superposées par un déplacement horizontal. Ces sigmoïdes seraient cependant légèrement moins redressées que dans la figure 1.
6. Modèle basé sur les logits des catégories adjacentes
106Une troisième approche pour les données ordinales prend en compte les probabilités suivantes :
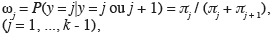
107pour lesquelles les logits sont :
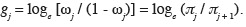
108Ces logits, appelés logits des catégories adjacentes (adjacent-categories logits), sont équivalents aux logits utilisés dans la régression binaire pour laquelle la catégorie correspondant à l'évènement serait la catégorie y = j et l'autre catégorie serait la catégorie y = j + 1. Ils sont exprimés en fonction de x, en considérant, ici aussi, que les coefficients de régression sont constants :
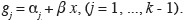
109Bien que le modèle des catégories adjacentes soit un cas spécial du modèle logit nominal, celui-ci ne permet pas d'imposer les contraintes appropriées par la méthode du maximum de vraisemblance. Par contre, si les données sont groupées dans une table de contingence, il peut être ajusté par la méthode des moindres carrés pondérés (Allison, 1999).
110Les odds sont égaux à :
111πj / πj+1 = exp(gj)
112et les odds ratios sont identiques pour les différentes catégories de y :
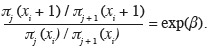
113À partir des odds, c'est-à-dire des rapports de probabilités pour des catégories adjacentes :
114πj / πj + 1 = exp(gj),
115on peut retrouver les probabilités d'appartenance aux catégories :
116πj = exp (gj + ... + gk - 1) / D
117avec : D = 1 + [exp (g1 + ... + gk - 1) + exp (g2 + ... + gk - 1) + ... + exp (gk - 1)]
118et πk = 1 - (π1 + ... + πk - 1).
119Pour ajuster le modèle aux données de l'exemple avec le logiciel SAS, les altitudes ont été regroupées en trois classes : la classe 1 comprend les valeurs inférieures à 285 m, la classe 2 les valeurs comprises entre 285 m et 400 m et la classe 3, les valeurs supérieures à 400 m. Les trois classes ainsi obtenues présentent des effectifs de même ordre de grandeur.
120Les résultats suivants ont été obtenus :
121g1 = 0,2795 - 0,6633 x,
122g2 = 2,2027 - 0,6633 x
123et g3 = 2,2950 - 0,6633 x.
124Le tableau 5 donne les probabilités d'appartenance aux différentes catégories ainsi que les odds, c'est-à-dire les rapports des probabilités des classes successives.
125L'odds ratio est égal à :
126exp(-0,6633) = 0,515.
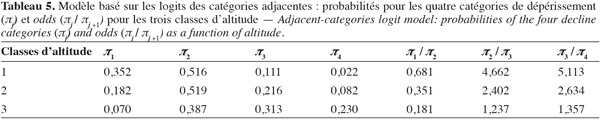
127Cela signifie donc que le rapport entre la probabilité d'être dans une catégorie et la probabilité d'être dans la catégorie immédiatement supérieure est divisée par deux quand on augmente d'une classe d'altitude, comme le montrent les résultats du tableau 5.
7. Discussion
128Pour une variable à expliquer y à plus de deux catégories ordonnées, nous avons présenté trois modèles (§ 4, 5 et 6). Ceux-ci diffèrent par les probabilités et donc aussi par les logits qui sont modélisés. Le tableau 6 résume les situations examinées. Il reprend également le modèle nominal, à titre de comparaison.

129Il faut tout d'abord noter que d'autres modèles équivalents à ceux présentés auraient pu être définis. Ainsi, par exemple, pour le modèle basé sur les logits cumulés, on pourrait s'intéresser aux probabilités P (y > j) pour lesquelles les logits seraient :
130loge [(πj + 1 + ... + πk)] / (π1 + ... + πj)].
131Par rapport au cas repris au § 4, le signe des coefficients des équations donnant les logits serait changé. De même, dans le cas des catégories adjacentes, on pourrait définir les probabilités d'intérêt :
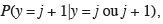
132ce qui conduirait également à un changement de signe des coefficients des fonctions logistiques, par rapport au modèle présenté au § 6.
133D'autre part, les modèles examinés permettent tous d'estimer les probabilités d'appartenance aux différentes catégories πj. Pour l'exemple traité, on constate d'ailleurs une forte similarité des πj pour le modèle nominal et pour les deux premiers modèles pour catégories ordinales, le troisième modèle ne pouvant pas être comparé car la variable altitude a été groupée en trois classes.
134Pour les différents modèles proposés, on a toujours considéré, par simplicité, que les logits évoluent de façon linéaire en fonction d'une seule variable x. Comme signalé dans l'introduction, les modèles peuvent être étendus au cas de plusieurs prédicteurs. Ces prédicteurs peuvent correspondre à des caractéristiques différentes ou à des fonctions de caractéristiques, comme des variables élevées au carré pour tenir compte d'effets non linéaires ou des produits de variables pour tenir compte d'interactions.
135Comparée au modèle pour données nominales, la prise en compte de l'ordre des catégories permet de réduire le nombre de paramètres, puisqu'on considère que les coefficients de régression sont constants pour les différentes fonctions logistiques. Cette parcimonie dans le nombre de paramètres est un avantage pour autant que l'hypothèse de parallélisme des fonctions logistiques soit réaliste. Ce parallélisme des fonctions correspond à la constance des odds ratios. Dans les tableaux 3, 4 et 5, la constance des odds ratios s'est traduite par un rapport constant entre valeurs successives dans les trois dernières colonnes de chacun des tableaux, quelle que soit la colonne considérée, et la différence entre les trois modèles se situe dans la définition des odds (tableau 6).
136On notera qu'il existe des tests permettant de vérifier les hypothèses de parallélisme. Des informations à ce sujet et sur la stratégie de recherche de modèles lorsque l'hypothèse de parallélisme est rejetée sont données par Brant (1990), Clogg et al. (1994), Long (1997), Allison (1999) et O'Connell (2000).
137Indépendamment du respect du parallélisme des fonctions logistiques, le choix d'un modèle de régression ordinale préférentiellement à un autre dépend aussi de la simplicité de l'interprétation des résultats, en relation avec l'objectif de l'étude. Si l'interprétation d'un type d'odds ratios particulier est un objectif majeur de l'étude, c'est ce type d'odds ratios qui sera évidemment retenu pour la simplicité qui en découle dans l'interprétation. En effet, même s'il est toujours possible de calculer a posteriori des odds ratios d'un type donné à partir des πj, alors qu'un autre type a été utilisé dans les modèles, il est évidemment beaucoup plus simple d'interpréter une seule valeur que d'être confronté à des odds ratios qui varient avec x et avec j.
138Ainsi, on préférera le modèle basé sur les logits cumulés si le but de l'étude est de clarifier la tendance, plutôt croissante ou décroissante, en fonction de x, de la probabilité d'avoir atteint un niveau donné de y (Agresti, 2002). Le modèle basé sur les catégories adjacentes supérieures cumulées sera plus utile dans des études de développement lorsque l'objectif principal est l'identification des facteurs associés au fait d'être dans une catégorie faible, sachant qu'un certain niveau a déjà été atteint (O'Connell, 2000). Les logits des catégories adjacentes seront utiles pour rechercher quelles sont les variables explicatives qui peuvent au mieux prédire la probabilité d'être dans une catégorie plutôt que dans la catégorie suivante.
139La réalisation des calculs ne pose pas de problèmes particuliers avec les logiciels tels que SAS, Minitab ou R pour la régression binaire, la régression nominale et la régression ordinale basée sur les logits cumulés. Pour ces modèles, les procédures ou les commandes des logiciels donnent directement les résultats. Pour le modèle basé sur les logits des catégories supérieures cumulées, les logiciels nécessitent un recodage des données, suivi de l'ajustement d'un modèle binaire sur données recodées.
140Quant au modèle basé sur les logits des catégories adjacentes, il n'est pas disponible dans Minitab. Par contre, il peut être ajusté par la procédure CATMOD de SAS ou par la fonction ACAT de R, qui utilisent la méthode des moindres carrés pondérés dont le point de départ est une table de contingence (Clogg et al., 1994 ; SAS Institute, 1995 ; Allison, 1999 et Stokes et al., 2000). C'est la raison pour laquelle, au § 6, la variable altitude a été recodée.
141Enfin, on notera également que les options par défaut des logiciels peuvent varier et conduire à des résultats à première vue différents mais en réalité tout à fait équivalents. Ces variantes peuvent se marquer, par exemple, sur les modalités de référence ou sur la définition des probabilités qui sont modélisées.
Bibliographie
Agresti A., 2002. An introduction to categorical data analysis. New York, USA: Wiley.
Allison P.D., 1999. Logistic regression using SAS system: theory and application. Cary, NC, USA: SAS Institute.
Brant R., 1990. Assessing proportionality in the proportional odds model for ordinal logistic regression. Biometrics, 46, 1171-1178.
Clogg C.C. & Shihadeh E.S., 1994. Statistical models for ordinal variables. Thousand Oaks, CA, USA: Sage.
Collett D., 1999. Modelling binary data. London: Chapman & Hall/CRC.
Duyme F. & Claustriaux J.J., 2006. La régression logistique binaire. Notes de statistique et d'informatique. Gembloux, Belgique : Faculté universitaire des Sciences agronomiques de Gembloux.
Gillet A., 2005. Influences stationnelle, sylvicole et spécifique sur le dépérissement des chênes indigènes (Quercus robur L. et Quercus petraea [Matt.] Liebl.) en Région Wallonne. Mémoire : Faculté universitaire des Sciences agronomiques de Gembloux (Belgique).
Gillet A., 2007. Régression logistique polychotomique ordinale. Travail de fin d'étude réalisé dans le cadre du diplôme d'Études approfondies en Statistique et Informatique appliquées : Faculté universitaire des Sciences agronomiques de Gembloux (Belgique).
Hosmer D.W. & Lemeshow S., 2000. Applied logistic regression. New York, USA: Wiley.
Long J.S., 1997. Regression models for categorical and limited dependent variables. Thousand Oaks, CA, USA: Sage.
O'Connell A., 2000. Methods for modelling ordinal outcome variables. Meas. Eval. Counseling Dev., 33(3), 170-193.
SAS Institute, 1995. Logistic regression examples using SAS system. Cary, NC, USA: SAS Institute.
Stokes M.E., Davsi C.S. & Koch G.G., 2000. Categorical analysis using SAS System. 2nd ed. Cary, NC, USA: SAS Institute.
Pour citer cet article
A propos de : Adeline Gillet
Centre de Recherche Public Gabriel Lippmann. Département Environnement et Agro-biotechnologies. Rue du Brill, 41. L-4422 Belvaux (Grand-Duché du Luxembourg).
A propos de : Yves Brostaux
Université de Liège. Gembloux Agro-Bio Tech. Unité de Statistique, Informatique et Mathématique appliquées. Avenue de la Faculté d'Agronomie, 8. B-5030 Gembloux (Belgique).
A propos de : Rodolphe Palm
Université de Liège. Gembloux Agro-Bio Tech. Unité de Statistique, Informatique et Mathématique appliquées. Avenue de la Faculté d'Agronomie, 8. B-5030 Gembloux (Belgique). E-mail : Rodolphe.Palm@ulg.ac.be
